In network communication as well as in storage of data on a medium such as a disk, errors are inevitable to some degree. Today, data is organized according to some kind of code to allow detection and/or correction of errors. The simplest error-detecting device would be a checksum, which is the sum of a set of data (values) and is attached to the data to be recorded or transmitted. When reading or receiving, the sum is computed from the retrieved data and an error is detected if the sum does not match the checksum attached to the data. There are various schemes to allow not only detection but also correction of errors.
Before the computer age, transmission errors posed a serious problem in telegraphy and various schemes were devised to prevent errors. A so-called mutilation table, among others, was an ingenious scheme in that it allows not only detection but also correction of errors and it could represent all of a hundred thousands or more code word patterns (up to 264=456,976 patterns) with a single sheet.
The present article provides an overview of error prevention measures for telegraphy and explains mutilation tables, arguably the most advanced form of error protection for telegraphy.
Table of Contents
Error Prevention Measures before Mutilation Tables
Mutilation Table for Japanese Code
While errors were commonplace in telegraphy, an error in an ordinary telegram does not do much harm when a human reader could understand a correct message from the context. However, such error resiliency cannot be relied on for figures and coded messages.
When transmitting figures an error in one digit turns a number into a different one, potentially leading to a fatal mistake. A checksum as used for digital data today was also proposed for telegraphy. To the best knowledge of the present author, the first to describe a checksum for telegraphy was a codebook for cotton trade, Private Telegraphic Code (1871), which proposed appending the sum of the digits representing a plurality of price information (in units of 1/8). While Meyer's The Cotton Telegraph Code (1871) from the same year, editions of which would be used for many decades to come, proposed appending a check digit determined by a table and does not employ checksums, the same author's The General Telegraph Code (1874) for general vocabulary proposed a checksum of numbers 1-26 associated with each letter of a code word. (For individual codebooks mentioned herein, see another article.)
Meyer (1874) was aware that figures were prone to transmission errors and proposed transmitting a checksum after translating it into a code word. Such a practice of transmitting figures as code words in order to prevent transmission errors in figures came into common practice about this time. (Many codebooks at the time used common dictionary words rather than arbitrary sequences of figures or letters for representing plaintext words and phrases. The serial number assigned to each code word provided ready means for associating figures with words.) With words, an error may be readily corrected by a human reader.
Even with words, however, there are many cases in which an error in a single letter turns a word into a different one. The problem was not limited to code words representing figures but was relevant for transmission of code words in general. From about 1870, compilers of codebooks started to take care not to include code words with similar spelling or Morse code representation.
Soon this led to the idea of "two-letter differential", whereby any two code words are different at least in two letters. Hartfield's The Merchant's Code, extended and improved in America and Whitelaw's 14,000 Latin Words in Britain, both published in 1880, employed this two-letter differential. This new trend of error detection put into obsolescence the checksum scheme that emerged in the 1870s. (The appearance of three-letter code in the 1930s, for which two-letter differential was not feasible, revived the practice of using checksums.)
Error detection is one thing but error correction is quite another. Although two-letter differential ensures that one-letter errors result in patterns that are not found in the codebook and thus could be detected, correction of the error is not easy when the error occurs in the first or second letter of the code word. A new device to facilitate finding the correct code word was the so-called terminal index (also called "terminational order"), which lists all the code words contained in a codebook in the order of backward spelling and helps finding the correct code word when the latter part of the received code word is correct. It appears that the first to employ this scheme was 25,000 English Words (1879), for which Whitelaw was the publisher.

25,000 English Words above also provides a "Telegraph Detector", which lists telegraphically convertible letters. Such a listing is included in many codebooks and helps identifying the original letter when an error is found.

When the terminal index was introduced, the international telegraph regulations stipulated that code words had to be real words in any of the eight languages such as English, French, German, etc. The revision of the regulations in 1903, however, allowed artificially words as long as they were pronounceable (see another article). On the other hand, the maximum length allowed for a code word was ten letters. Thus, a new type of codebooks appeared, which consisted of code words all made of five letters and allowed combining two code words as one ten-letter code word to be transmitted, thus reducing the telegraph cost by half. Such a five-letter code opened a way to methodically structuring code words with a simple table, which also allowed detection and correction of errors.
To begin with, the principles of a mutilation table is now explained with a reduced alphabet having seven letters.

As illustrated above, a mutilation table consists of three sections: top-left, bottom-left, and bottom-right (or top-left, top-right, and bottom-right). The top-left section represents the first two letters, the bottom-left section represents the third letter, and the bottom-right section represents the last two letters. All the code words included in a codebook are formed according to this simple table. (Hence, a mutilation is also called a construction table.)
With such a mutilation table, given the first two and the last two letters, the third letter can be uniquely determined by identifying the column including the first two letters in the top-left section, identifying the row including the last two letters in the bottom-right section, and finding the letter at the intersection of the extensions of the column and the row in the bottom-left section. By using this relation, if any four letters of a five-letter code word are given, the remaining one letter can be identified. (While there are five candidates depending on which of the five letters is mutilated, the context helps identifying the correct one. Further, since not all the combinations of the table are used in a codebook, there may be less than five candidates.)
Unique determination of the remaining letter given four of the five letters means the code words constructed from this table satisfy the requirement of "two-letter differential." Otherwise, that is, if there were two code words which differ in only one letter, there would be two candidates given four letters.
Without a mutilation table, a code compiler who wishes to implement the two-letter differential would have to manually exclude code words which differ from other code words in only one letter. In contrast, constructing code words according to such a table automatically ensures that the two-letter differential between code words is achieved.
Possibly, code compilers hit upon the idea of constructing a code with such a table while they struggled to verify the two-letter differential with a terminal index.
A mutilation table, if properly constructed, may be used to exclude not only code words with one letter difference but also code words which differ only in transposition of two adjacent letters. Thus, if there is a code word AMNED, there is no such a code words such as ANMED, with M and N interchanged. Thus, such an interchange is sure to be detected.
Referring to the reduced mutilation table above, the condition that there are no code words with the first and second letter transposed is equivalent to a condition that a two-letter pair and its reversed version do not occur in one vertical column (the column is specified by the unchanged third letter). With the regular pattern as illustrated above, such a condition would be met if the number of squares in a column of the top-left section (i.e., the number of letters in the alphabet) is odd. (If it were even, reversed pairs occur in a column where the alphabetical interval between the first letter and the second letter is half the number of letters in the alphabet. For example, the interval between A and D is 3, which is half of 6.) See the red squares in the left drawing in the figure below.
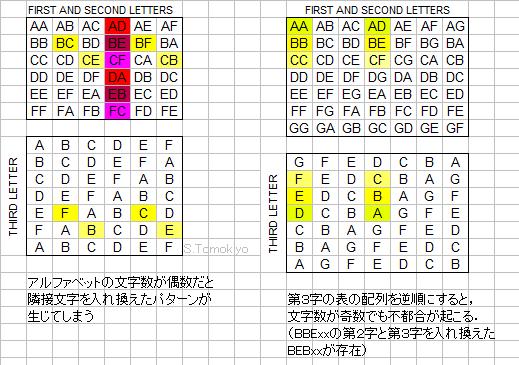
The condition of absence of code words with the second and third letters transposed is more complicated. Consider the case in which the second letter C as in BC is exchanged for the third letter F. It is required that C does not occur at the intersection of the vertical column of BF after the transposition and the horizontal row of the third letter F (the row is specified by the unchanged fourth and fifth letters). Graphically, for BC and BF in the top-left section, F and C shall not occur directly under them in the bottom-left section. Such a pattern would occur if the alphabetical increment from C to F is equal to the increment from F to C via wraparound (i.e., if the interval between the second and third letters is half the number of letters in the alphabet). If the number of letters were even, such a pattern would occur as illustrated in yellow in the left drawing in the figure above. (There are both BCFxx and BFCxx, which differ only in the transposition of C and F.) In contrast, if the number of letters is odd, such a pattern can be avoided.
It should be noted, however, that with a reversed order in the bottom-left section as in the right drawing in the above figure, the odd number of letters cannot avoid the problem. (The number of letters in the alphabet does not matter because wraparound does not count.) The mutilation table of Schofield below belongs to this type.
Now, since the common Latin alphabet has an even number (26) of letters, naive construction of a mutilation table would not do. Mutilation tables of codebooks after 1920 provide one measure or another to avoid the problem.
The simplest one is not to use one letter, e.g., Q, from the alphabet, thus making odd the total number of letters in the alphabet -- 25.
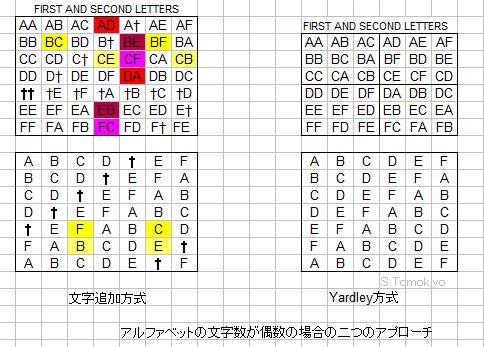
To the contrary, David Kahn, The Codebreakers p.848 describes a method to add one symbol, e.g., "†", in the alphabet to obtain an odd number of letters -- 27. By not using patterns including "†" among those constructed with such a table, transposition of adjacent letters can be avoided while the full 26 letters of the alphabet are employed. See the squares in red and yellow in the left drawing of the figure below, where the problematic patterns are staggered and thus do not cause problems.
Yardley et al. (described below) divides a 26x26 section into four 13x13 subsections, thereby obtaining an odd number of letters for each subsection.
To the best knowledge of the present author, the first mutilation table included in a codebook is "Analysis for Tracing Mutilations" of Schofield's Eclectic Phrase Code (1914, Kobe, Japan). While the copy the present author has seen is only the "6th reprint: printed by photo-zyncotype process from the original 1914 edition" of 1925 (with an introduction dated "December 1914"), there is no reason to doubt this statement on the title page, which also states "International Copyright Secured 1919. United States Copyright Secured 1920." Of these, the latter could be confirmed by Catalog of Copyright Entries for the Year 1920 (Google).

It is noted that Schofield does not advertise this mutilation table as anything novel. Possibly, it was already widely known among code compilers. (Even codebooks that do not include a mutilation table for the user may be constructed based on such a table. Electronic processing of the entire code words would allow verification of whether a given codebook is constructed based on such principles.) There is also a possibility that a scholarly article proposed such a scheme before it was employed in commercial codes.
The fact that Schofield's mutilation table does not avoid transposition of letters (as discussed above) also implicitly indicates it was an early one. For example, it allows code words OCOxx as well as OOCxx, which differ only in the transposition of the second and third letters. Omission of the letter Q is not for making an odd number of letters but probably in view of the pronounceability requirement described below. (Since Q requires U+vowel to follow it, the number of code words provided by use of Q may be very limited.)
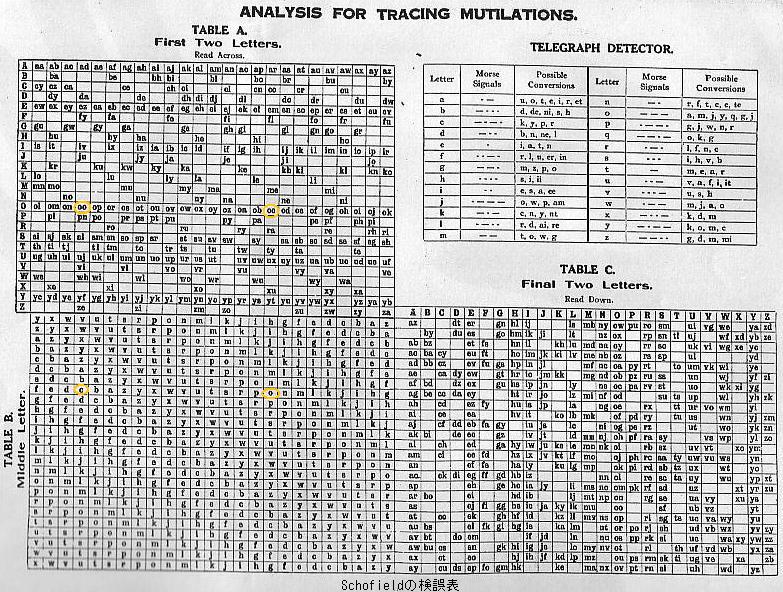
Schofield's mutilation table above has blanks here and there. Probably, this was to avoid letter combinations that cannot be pronounced (or that may be deemed unpronounceable by a telegraph office) because the international telegraph regulations required code words to be pronounceable until 1928. (As explained in another article, however, the pronounceability requirement could not be strictly enforced.) Among the codebooks listed below, those after 1930, when the pronounceability was no longer a requirement, do not have such blanks.
As seen by the fact that the ABC Code (6th ed.) published in 1920 still used a terminal index rather than a mutilation table, inclusion of a mutilation table in a codebooks was not yet common at the time. Adoption of a mutilation table appears to have been triggered by Yardley et al., Universal Trade Code (1921) and A. C. Meisenbach ("Acme"), Acme Commodity and Phrase Code (1923), in particular the latter, which was widely used in the years to come. (Abe (1949) repeats a hearsay that Universal was the first to employ this kind of mutilation table (p.10) but Schofield anticipate it in 1914, whch was registered in the US catalog of copyright entries in 1920. The War Department Telegraph Code of 1915 also had a mutilation table (see another article)).
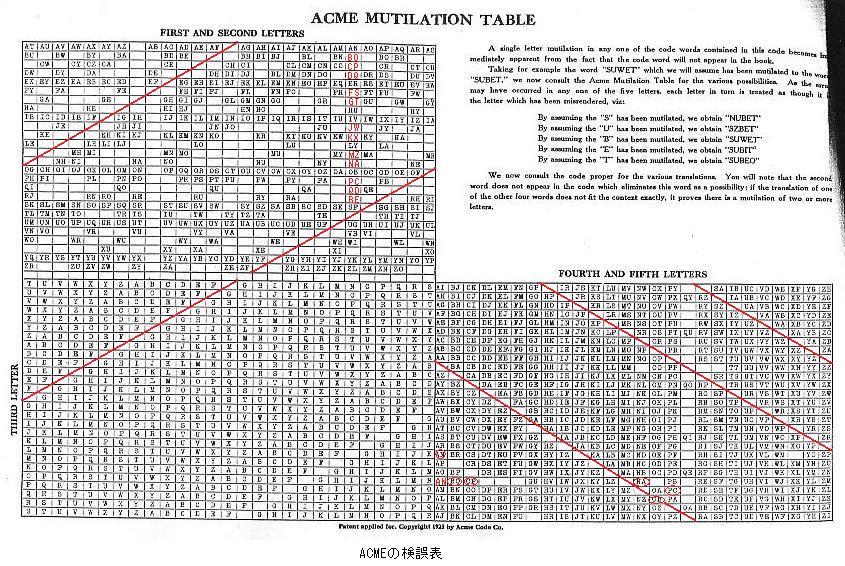
It is noted neither Yardley nor Acme advertised the mutilation table as a novel feature in itself. Yardley et al. simply says "If a message is mutilated, it can usually be restored by means of the Mutilation Table which will be found on the inside back cover."
The explanation of the Acme Mutilation Table asks the user to "Compare it with any other mutilation table and visualize" its advantages. Thus, it is clear that Acme does not claim priority for the mutilation table itself. The claimed advantage of the Acme Mutilation Table is "simplicity": "Instead of having to run through columns of tabulated letters which are mixed up without regard to any order, you are confronted in this Code with a table in which the First and Second letters are arranged in alphabetical order, the Third letter in similar order, and again The Fourth and Fifth in alphabetical order." If the "other mutilation tables" at the time had been like that of Nakayama (1938) below, such a claim might have some truth. However, when compared with those of Yardley et al. or Schofield, the Acme Mutilation Table does not seem to be new. The Acme Mutilation Table states "Patent applied for." It is wondered whether the application was granted. (The present author could not identify a patent in Google Patent search.)
Yardley et al. (1921) and Acme (1923) both claim there are no code words which differ only in transposition of adjacent letters but adopt different means to ensure it.
The "Mutilation Table" of Yardley et al. divides 26x26 sections (top-left and bottom-right) into four 13x13 subsections, respectively, resulting in an odd number of letters in each subsection.
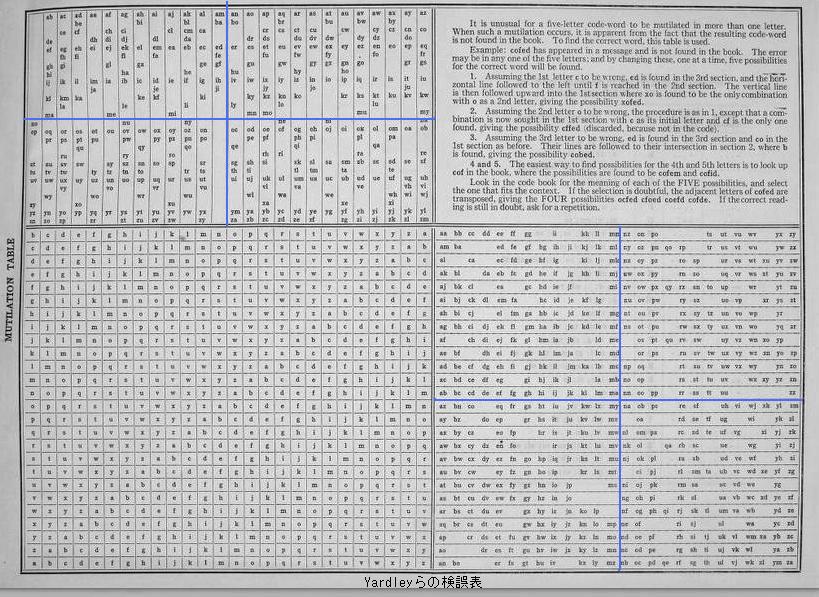
At a first glance, the "Acme Mutilation Table" appears to follow the scheme described by Kahn by inserting a symbol between F and G in the alphabet and replacing the pairs including a "†" with blanks. Actually, it is more complicated. For example, if the blanks in the column headed by AN were filled, there would be transposed patterns such as NA for AN, BO for OB, etc. in the same column. At a closer look, it is found that the top-left section has an odd number of columns (27) but an even number of rows (26).
In the bottom-right section, there is a blank in the leftmost column where AN should be. Probably, AN was displaced upwards by three squares because there is its transposed pattern NA in the same row. Further, the pattern dictates that there should be OB and PC, which are transposed patterns for BO and CP in the same row. However, the columns of O and P shows OB and PC are displaced downward out of the alphabetical order.
To summarize, the Acme Mutilation Table employs insertion of blanks in order to obtain an odd number of columns in the top-left section and an odd number of rows in the bottom-right section in order to avoid transposition of the second and third letters and the transposition of the third and fourth letters, respectively, while transposition of the first and second letters as well as that of the fourth and fifth letters are avoided by individually making blanks or displacing letter pairs.
The five-letter code words in Mitsubishi's codebook (1929) are adapted for the new telegraph regulations adoped in 1928 such that two five-letter code words form a 10-letter telegraph word conforming to the "Category A" of the regulations (see another article). The requirements of "Category A" for five- and ten-letter code words are as follows.
In order to be used in forming 10-letter code words conforming to the above definition, every 5-letter code word should include two vowels.
In simplified forms, the four mutilation tables are of the following patterns (V=vowel, C=consonant, X=don't care):
Table A1: VC-V-XX or CV-V-XX (for the latter case, the endings of the pattern XX=VC are not used)
Table A2: VC-C-VC or VC-C-CV or CV-C-VC or CV-C-CV (for the case of VC-C-CV, some additional restrictions are imposed)
Table B: VV-C-XX
Table C: CC-V-XX
The Usage points out that if two code words from Table C form a 10-letter code word, the "three-vowel" condition may not be met and explains, in such cases, they should be sent as two separate 5-letter code words.

The complicated Category A was abolished in the 1932 revision of the telegraph regulations and thereafter, telegraph words were limited to the length of five letters, to which no restrictions in form were imposed.
New Boe Code (1937) has its "Table for Correction of Mutilated Codewords" (see Bellovin, Fig. 6), which has an odd number (25) of letters by omitting Q.
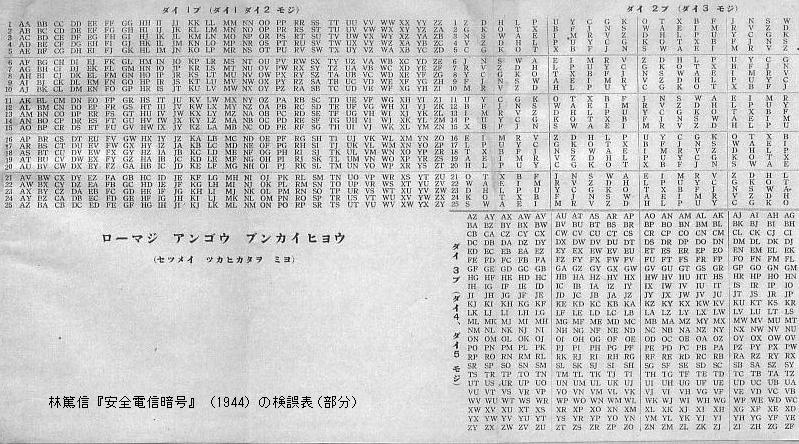
Hayashi Atsunobu, Anzen Denshin Ango [Secure Telegraphic Code] (1944, Japan) has its "Romanized Code Analysis Table", which is similar to this but has irregular arrangement of letters within each column in the top-right section. Hayashi claims his code prevents not only transposition of two adjacent letters but also transposition of two letters separated by one intervening letter. (I have not verified this feature.)
Bentley's Second (1929) has a "Mutilation Table", which is similar to this (25 letters without Q) but has irregular arrangement of letters for the 2nd, 3rd, and 5th letters. Bentley claims his code words are selected such that "reversal of any pair of consecutive letters", "reversal of any three consecutive letters" [i.e., transposition of two letters separated by one intervening letter], or "mutilation of any pair of consecutive letters ... by a pause-error in transmitting by Morse" [presumably referring to such pairs as ER ". ._." vs. UE ".._ ."] will result in a pattern not used in the codebook and thus will surely be detected.
ABC Code (7th ed.) has its "Key to Codewords", which has top-left, top-right, and bottom-right sections and uses a 25-letter alphabet. The top-left section has 25 rows and 26 columns, i.e., one more column than the rows. Further, its arrangement of letters for the second letter look irregular.
Nakayama Hisami, Wao Shoji Denpo Ango (Japanese Commercial Code for International Use) (1938) has a mutilation table, which is based on 26x26, i.e., an even number of letters. It appears irregular arrangement of letters is used to prevent transposition of adjacent letters (yet to be verified).
The following is a "Key to Codewords" from ABC7.

The following is a mutilation table from Nakayama (1938).

The following is a mutilation table from Hayashi (1944).
Mutilation tables for alphabetical five-letter codes, which were the norm at the time, have been described above. In Japan, some codebooks introduced mutilation tables for code words made of kana (Japanese syllabic characters) in the 1940s. (For individual Japanese codes, see another article.)
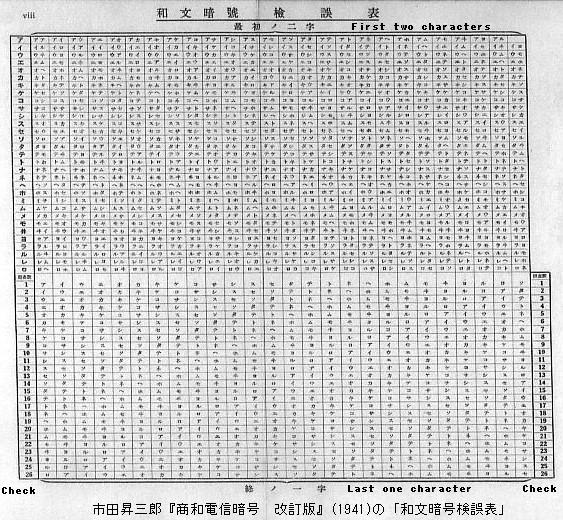
Ichida Shozaburo, Showa Denshin Ango, Revised Edition (Ichida's Improved Japanese Code) (1941) assigns to each code word a check number (1-26). The sum (3-78) of the check numbers for three code words is translated to a character ("check character") with a table and is transmitted with the code words. The recipient restores the check number and uses the mutilation table to check for errors.
This mutilation table is constructed to allow the third kana of a three-kana code word given the first two kana and the check number. This can be used to identify the remaining kana given any two of a three-kana code word.
Regarding the restoring of the check number, although only the sum of three check numbers is transmitted as the check character, if two of the three code words are correct, their check numbers and the transmitted sum allows identifying the check number for the remaining code word.
This codebook also includes alphabetical three-letter code words and provides a similar mutilation table for them. Nakayama Hisami, Nihon Tsusho Ango (Japanese Trade Code for Universal Use) (1950), which employs alphabetical three-letter code words, also includes a similar table. (This kind of mutilation table for alphabetical three-letter code had been employed in Paramount Simple-check Three Letter Code (1934) by H. Morioka, who claimed it was "completely different from the one so far devised.")
Nakayama Hisami, Shoji Denpo Ryakugo: Jisashiki Niji-sei (1952) is a two-kana code ("Niji-sei"). Its mutilation table shows combinations of two kana, with each row assigned a check number 0-46. Its use is similar to that of Ichida (1938) or Nakayama (1950).
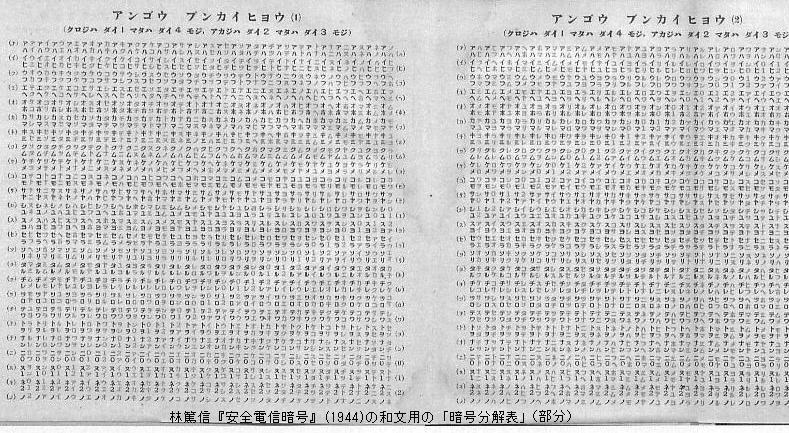
Hayashi Atsunobu, Anzen Denshin Ango (1944) described above also includes a mutilation table for Japanese four-kana code. The table lists possible combinations of the first/fourth character (black) and the second/third character (red). Basically, the vertical axis has 46 kana "a"-"n" plus "0", "1", and "2" (this codebook includes "0", "1", and "2" among kana for constructing code words) in black in an interleaved order and the horizontal axis has "a"-"n", "0", "1", and "2" in red with progressive displacement. Each intersection has two kana (black + red). Since the first two kana and the latter two kana of a four-kana code must belong to the same virtical column, when three of the four kana of a code word are given, either the first or the latter two-kana pair can be identified and the one unknown kana could be determined within the same virtical column.
Hayashi Mitsuharu, Wabun Denryau Ango Cho (1939) has a "mutilation checking table", which not only serves for error detection but also for ambiguity resolution of code. This codebook is basically a two-kana code but uses the same two-kana combinations in five sections by using voicing marks or indicator code words. Still, such voicing marks or indicator code words may be eliminated by using a pairing indicator letter, which specifies sections corresponding to the preceding pair of two-kana code words.